SIAT新闻网

Research | 深圳先进院提出面向肺癌的两阶段 TNM可问责的报告自动生成技术
近日,中国科学院深圳先进技术研究院(以下简称“深圳先进院”)生物医学与健康工程研究所、医学成像科学与技术系统全国重点实验室胡战利研究员等,联合广东省人民医院姜磊主任团队、哈尔滨工程大学姚晓辉教授团队,在全身 PET/CT 报告自动生成领域取得重要进展。
研究团队提出了面向肺癌的两阶段、TNM可问责的报告自动生成技术。在生成流畅报告草稿的同时,将原发肿瘤、淋巴结及远处转移等分期关键结论关联到显式、可检视的疾病分类标签与文本证据之上,使医生能够快速核验其中的高风险陈述,从而减轻医生PET/CT 判读负担,为可信 AI 报告系统的临床落地提供了可行路径。相关成果以"TNM-accountable Whole-body 3D FDG PET/CT report drafting in lung cancer cohorts via structured impressions and organ-wise exemplar synthesis"为题,发表在知名期刊Research(IF=12.9)上。
全身 PET/CT 可同时提供病灶的代谢与解剖信息,是肺癌诊断与分期的核心手段。TNM 分期直接决定治疗策略与预后:肺癌患者的 5 年生存率从 I 期的 70% 以上降至 IV 期的不足 10%。然而,PET/CT 报告的撰写负担沉重,医生需逐层判读覆盖全身的三维容积图像,将每一处异常摄取与对应解剖结构精确匹配,并形成包含病灶大小、SUVmax 等定量指标的专业报告。
针对上述问题,研究团队提出两阶段 RIDE 框架(图 1)。该方法的核心思想是:将“准确且可核验的内容”与“完整叙述的生成”相解耦。
第一阶段由双通道三维编码器分别从 PET 与 CT 学习融合的代谢-解剖表征,快速生成面向 TNM 的结构化印象,以清单形式显式列出原发灶的肺叶定位、形态、摄取分级、SUVmax 与大小分级,以及淋巴结与转移的分期关键证据。
第二阶段以该结构化印象作为指导,自去标识化的范例库中按器官分层检索相似报告片段,约束大语言模型仅依据结构化印象与检索证据合成完整报告(图2)。其中,分期关键陈述设为硬约束;对证据不充分之处,则采用留有余地的审慎表述,避免缺乏依据的臆测性描述。
为了系统验证泛化能力,研究团队构建了多中心数据集,涵盖三家医院共 1583 名疑似或确诊肺癌患者,每例均包含完整的全身 PET/CT 影像与对应报告。研究结果显示,在包含外部数据的多中心测试集上,RIDE 取得最优的整体报告生成性能,常规语言指标全面领先,BLEU-4 提升约 17%。同时,研究团队提出临床报告能力矩阵,从代谢检出、病灶定位和恶性分类三个维度量化临床准确性。
未来,研究团队将开展前瞻性多读者研究,评估真实工作流中的整合、交互与安全性,并探索将该框架推广至其他病种。
深圳先进院胡战利研究员、广东省人民医院姜磊主任和哈尔滨工程大学姚晓辉教授为论文共同通讯作者。深圳先进院客座硕士生王航、谢行雨副研究员和广东省人民医院刘恩涛副主任医师为论文共同第一作者。该研究工作得到了医学成像科学与技术系统全国重点实验室、国家自然科学基金(数学天元重点专项)、国家重点研发计划(重大科学仪器设备研发重点专项)等项目的资助。
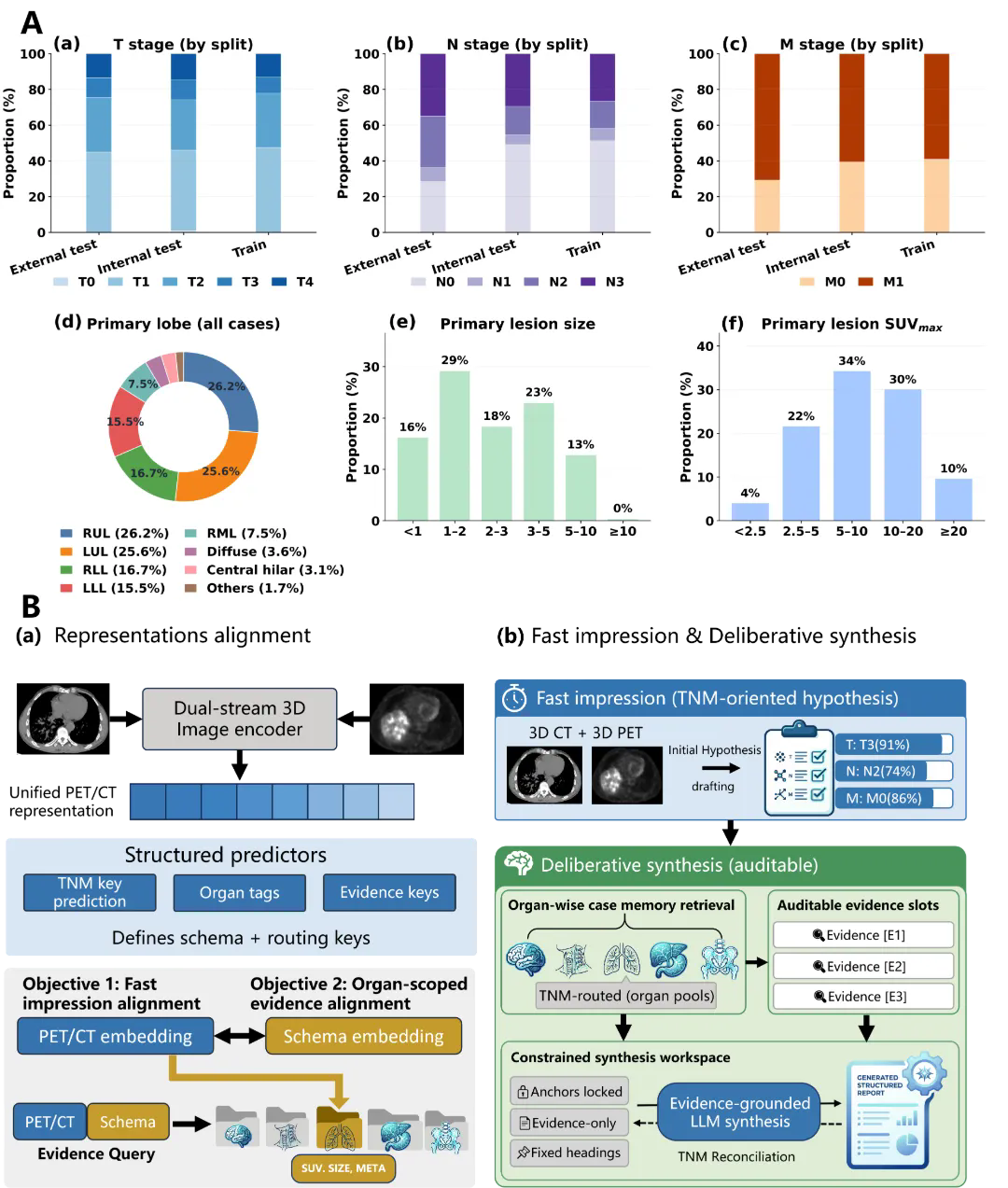
图1:数据集与两阶段RIDE框架。

图2:一个具有代表性的PET/CT病例的可追溯性审议式综合分析。
附件下载:
